(报告出品方/作者:国信证券,熊莉)
算力芯片研究框架
计算芯片是算力时代下智能网联汽车的核心
计算芯片可分为 MCU 芯片与 SoC 芯片。随着汽车 EE 架构的不断革新,汽车半导体高速发展,按功能不同,汽车半导体可分为汽车芯片和功率半导体,而在汽车芯片中,最重要的是计算芯片,按集成规模不同,可分为MCU 芯片与SoC 芯片。MCU(Micro Control Unit)微控制器,是将计算机的CPU、RAM、ROM、定时计数器和多种 I/O 接口集成在一片芯片上,形成芯片级的芯片;而SoC(SystemonChip)指的是片上系统,与 MCU 不同的是,SoC 是系统级的芯片,它既像MCU 那样有内置RAM、ROM,同时又可以运行操作系统。
智能化趋势驱动汽车芯片从 MCU 向 SoC 过渡。自动驾驶对汽车底层硬件提出了更高的要求,实现单一功能的单一芯片只能提供简单的逻辑计算,无法提供强大的算力支持,新的 EE 架构推动汽车芯片从单一芯片级芯片MCU 向系统级芯片SoC过渡。

SoC 市场高速发展,预计 2026 年市场规模达到 120 亿美元。汽车智能化落地加速了车规级 SoC 的需求,也带动了其发展,相较于车载MCU 的平稳增长,SoC市场呈现高速增长的趋势,根据 Global Market Insights 的数据,预计全球车规级SoC 市场将从 2019 年的 10 亿美元达到 2026 年的 160 亿美元,CAGR 达到35%,远超同期汽车半导体整体增速。
传统 MCU:MCU 需求稳步增长,海外寡头长期垄断
MCU 是 ECU 的运算大脑。ECU(Electronic Control Unit,电子控制单元)是汽车 EE 架构的基本单位,每个 ECU 负责不同的功能。MCU 芯片嵌入在ECU 中作为运算大脑。当传感器输入信号,输入处理器对信号进行模数转换、放大等处理后,传递给 MCU 进行运算处理,然后输出处理器对信号进行功率放大、数模转换等,使其驱动如电池阀、电动机、开关等被控元件工作。
MCU 根据不同场景需求,有 8 位、16 位和 32 位。8 位MCU 主要应用于车体各子系统中较低端的控制功能,包括车窗、座椅、空调、风扇、雨刷和车门控制等。16位 MCU 主要应用为动力传动系统,如引擎控制、齿轮与离合器控制和电子式涡轮系统等,也适合用于底盘机构上,如悬吊系统、电子动力方向盘、电子刹车等。32 位 MCU 主要应用包括仪表板控制、车身控制以及部分新兴的智能性和实时性的安全功能。在目前市场的主流 MCU 当中,8 位和 32 位是最大的两个阵营。
MCU 市场稳步发展,预计 2026 年全球规模达 88 亿美元。在市场规模上,全球MCU市场呈现稳步发展的趋势,根据 IC Insights 估计,预计全球MCU 市场规模从2020年的 65 亿美元达到 2026 年的 88 亿美元,CAGR 达到5.17%,略低于同期汽车半导体增速。同时我国 MCU 发展与世界齐头并进,预计2026 年市场规模达到56亿元,CAGR 达到 5.33%,与世界同期基本持平。

智能座舱 SoC:高通在中高端数字座舱呈现垄断局面
一芯多屏不断普及,高通在中高端数字座舱呈现垄断地位。伴随着数字座舱渗透率不断提升,车内数量不断增加,屏幕尺寸不断增大,智能座舱快速普及,一芯多屏逐渐成为主流,也带动智能座舱 SoC 芯片的快速放量。SoC 应用在智能汽车上主要有智能座舱以及自动驾驶两方面,相比于自动驾驶SoC,座舱域SoC由于要求相对较低,成为 SoC 落地智能汽车的先行者。高通、恩智浦、德州仪器、英特尔、联发科等各家不断更新其座舱 SoC 产品,在中高端数字座舱域,目前高通呈现垄断地位。目前,高通已经赢得全球领先的 20+家汽车制造商的信息影音和数字座舱项目,高通骁龙 820A 和 8155 两代平台成为众多车型数字座舱平台的主流选择,高通也将推出的第四代座舱 SoC SA8295,在算力、I/O 能力等方面表现出色,不断稳固其在中高端数字座舱的稳固地位。
自动驾驶 SoC:CPU+XPU 是当前主流,英伟达当前领先
自动驾驶芯片是指可实现高级别自动驾驶的 SoC 芯片。随着自动驾驶汽车智能化水平越来越高,需要处理的数据体量越来越大,高精地图、传感器、激光雷达等软硬件设备对计算提出更高要求,因此在 CPU 作为通用处理器之外,增加具备AI能力的加速芯片成为主流,常见的 AI 加速芯片包括GPU、ASIC、FPGA 三类。CPU 作为通用处理器,适用于处理数量适中的复杂运算。CPU 作为通用处理器,除了满足计算要求,还能处理复杂的条件和分支以及任务之间的同步协调。CPU芯片上需要很多空间来进行分支预测与优化,保存各种状态以降低任务切换时的延时。这也使得它更适合逻辑控制、串行运算与通用类型数据运算。以GPU与CPU进行比较为例,与 CPU 相比,GPU 采用了数量众多的计算单元和超长的流水线,但只有非常简单的控制逻辑并省去了 Cache。而 CPU 不仅被Cache 占据了大量空间,而且还有有复杂的控制逻辑和诸多优化电路,相比之下计算能力只是很小的一部分。
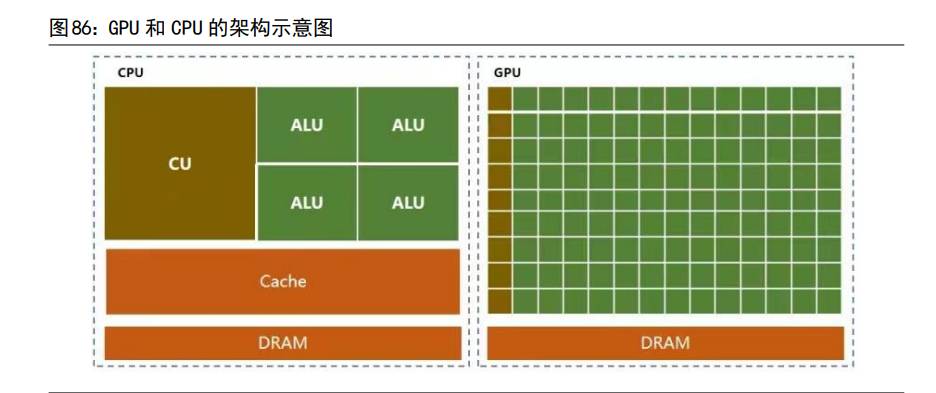
“CPU+XPU”是当前自动驾驶 SoC 芯片设计的主流趋势。根据XPU 选择不同,又可以分为三种技术路线:CPU+GPU+ASIC、CPU+ASIC 以及CPU+FPGA 三类。(1)“CPU+GPU+ASIC”,主要代表英伟达、特斯拉FSD 以及高通Ride。英伟达Xavier 和特斯拉 FSD 采用“CPU+GPU+ASIC”的设计路线,英伟达Xavier以GPU为计算核心,主要有 4 个模块:CPU、GPU、以及两个ASIC 芯片Deep LearningAccelerator(DLA)和 Programmable Vision Accelerator(PVA);特斯拉FSD芯片以 NPU(ASIC)为计算核心,有三个主要模块:CPU、GPU 和Neural ProcessingUnit(NPU)。
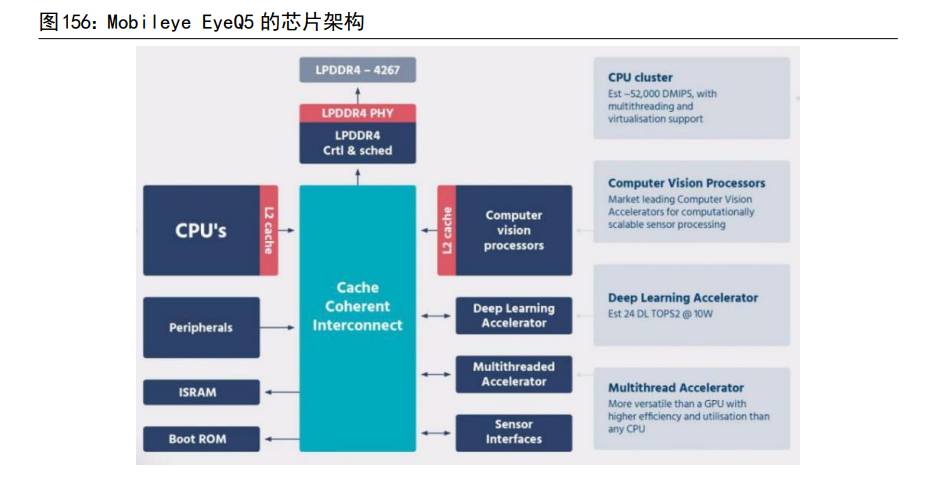
(2)“CPU+ASIC”,主要代表 Mobileye EyeQ5 系列和地平线征程系列。MobieyeEyeQ5 和地平线征程系列采用“CPU+ASIC”架构,EyeQ5 主要有4 个模块:CPU、Computer Vision Processors(CVP)、Deep Learning Accelerator(DLA)和Multithreaded Accelerator(MA),其中 CVP 是针对传统计算机视觉算法设计的ASIC;地平线自主设计研发了 Al 专用的 ASIC 芯片Brain Processing Unit(BPU)。
(3)CPU+FPGA,主要代表 Waymo。与其余厂商不同,Waymo 采用“CPU+FPGA”的架构,其计算平台采用英特尔 Xeon12 核以上 CPU,搭配Altera 的Arria 系列FPGA。

目前各家发布的最新芯片平台均可以支持 L3 或 L4 级的算力需求,英伟达当前处于领先位置。英伟达单颗 Orin 的算力可以达到 254TOPS,而2022 年落地的车型中搭载 4颗Orin的蔚来 ET7和威马M7其巅峰算力将超过1000TOPS,高通骁龙Ride平台的巅峰算力预计在 700-760TOPS,Mobileye 也推出了面向高阶自动驾驶的EyeQ6 Ultra,算力达到 176 TOPS,当前各家最先进的算力平台均可以支持L3或L4 级的算力需求。从相关量产车型来看,英伟达Orin 成为当下的主流选择,Mobileye 正在逐渐掉队。
评价框架:芯片性能,算力、能耗、效率缺一不可
评估芯片的性能,一般采用 PPA 即 Power(功耗),Performance(性能),Aera(面积)三大指标来衡量性能。而智能驾驶领域,峰值算力成为衡量自动驾驶芯片的最主要指标,常见的指标有 TOPS、FLOPS、DMIPS 三种:
TOPS(Tera Operation Per Second):每秒完成操作的数量,乘操作算一个 OP,加操作算一个 OP。TOPS 的物理计算单位是积累加运算(MultiplyAccumulate, MAC),1 个 MAC 等于 2 个 OP。TOPS 表示每秒进行1 万亿次操作。
FLOPS(Floating-Point Operations Per Second):每秒可执行的浮点运算次数的字母缩写,它用于衡量计算机浮点运算处理能力。浮点运算,包括了所有涉及小数的运算。MFLOPS(MegaFLOPS)等于每秒1 百万次的浮点运算;GFLOPS(GigaFLOPS)等于每秒 10 亿(=10^9)次的浮点运算;TFLOPS(teraFLOPS)等于每秒 1 万亿次的浮点运算。
DMIPS(Dhrystone Million Instructions Per Second):是测量处理器运算能力的最常见基准程序之一,常用于处理器的整型运算性能的测量。MIPS:每秒执行百万条指令,用来计算同一秒内系统的处理能力,即每秒执行了多少百万条指令。不同的 CPU 指令集不同、硬件加速器不同、CPU 架构不同,导致不能简单的用核心数和 CPU 主频来评估性能,Dhrystone 作为统一的跑分算法,DMIPS 比 MIPS 的数值更具有意义。
(1)智能座舱 SoC: DMIPS 衡量 CPU 算力的主要单位是 DMIPS,基本上SoC 高于20,000 DMIPS才能流畅地运行智能座舱的主要功能,如 AR 导航或云导航、360 全景、播放流媒体、ARHUD、多操作系统虚拟机等。GPU 方面,100 GFLOPS 的算力就可以支持3个720P的屏幕。一般来说,CPU 高于 20,000 DMIPS,GPU 高于100 GFLOPS 的SoC就是智能座舱 SoC 芯片。 (2)自动驾驶 SoC: TOPS 峰值算力体现的只是芯片的理论上限,不能代表其全部性能。自动驾驶需要的计算机视觉算法是基于卷积神经网络实现的,而卷积神经网络的本质是累积累加算法(Multiply Accumulate,MAC),实现此运算操作的硬件电路单元,被称为“乘数累加器”。这种运算的操作,是将乘法的乘积结果b*c 和累加器a的值相加,再存入累加器 a 的操作。TOPS = MAC 矩阵行* MAC 矩阵列* 2 *主频,TOPS峰值算力反映的都是 GPU 理论上的乘积累加矩阵运算算力,而非在实际AI应用场景中的处理能力,具有很大的局限性。以英伟达的芯片为例,Orin、Xavier的利用率基本上是 30%左右,而采用 ASIC 路线,ASIC 芯片针对不同的神经网络模型去优化,基本上可以做到 60%~80%之间。

地平线提出最真实的 AI 效能由理论峰值计算效能、有效利用率、AI 算法效率组成。地平线在 2020 全球人工智能和机器人峰会提出了芯片AI 性能评估方式MAPS(Mean Accuracy-guaranteed Precessing Speed),地平线认为最真实的AI效能实际上由三要素组成,分别为理论峰值计算效能、有效利用率、AI 算法效率。(1)理论峰值计算效能,TOPS/W、TOPS/$,即传统理论峰值衡量的方法;(2)芯片有效利用率,把算法部署在芯片上,根据架构特点,动用编译器等系统化解决一个极其复杂的带约束的离散优化问题,而得到一个算法在芯片上运行的实际利用率,这是软硬件计算架构的优化目标;(3)AI 算法效率,每消耗一个TOPS算力,能带来多少实际的 AI 算法的性能,它体现的是AI 算法效率的持续提升。(报告来源:未来智库)
汽车软件研究框架
操作系统 OS:QNX+Linux 或 QNX+Android 是当前的主流趋势
在智能网联时代,车机操作系统 OS(operating system)按下游应用划分,可以分为车控 OS 和座舱 OS 两大类:(1)车控 OS:主要负责实现车辆底盘控制、动力系统和自动驾驶,与汽车的行驶决策直接相关;(2)座舱OS:主要为车载信息娱乐服务以及车内人机交互提供控制平台,是汽车实现座舱智能化与多源信息融合的运行环境,不直接参与汽车的行驶决策。 对于车控 OS 而言,可分为嵌入式实时操作系统 RTOS 和基于POSIX 标准的操作系统。(1)嵌入式实时操作系统 RTOS:传统车控 ECU 中主控芯片MCU 装载运行的嵌入式 OS,面向经典车辆控制领域,如动力系统、底盘系统和车身系统等。要求实时程序必须保证在严格的时间限制内响应,特点包括速度快,吞吐量大,代码精简,代码规模小等;(2)基于 POSIX 标准的操作系统:主要面向智能驾驶系统,主要满足其高通信和低延时的要求。
汽车电控 ECU 必须是高稳定性的嵌入式实时性操作系统,主流的嵌入式实时操作系统都兼容 OSEK/VDX 和 Classic AUTOSAR 这两类汽车电子软件标准。嵌入式实时操作系统具有高可靠性、实时性、交互性以及多路性的优势,系统响应极高,通常在毫秒或者微秒级别,满足了高实时性的要求。目前,主流的嵌入式实时操作系统都兼容 OSEK/VDX 和 Classic AUTOSAR 这两类汽车电子软件标准。欧洲在上世纪 90 年代提出了汽车电子上分布式实时控制系统的开放式系统标准OSEK/VDX。但随着技术、产品、客户需求等的升级,OSEK 标准逐渐不能支持新的硬件平台。2003 年,宝马、博世、大陆、戴姆勒、通用、福特、标志雪铁龙、丰田、大众 9 家企业作为核心成员,成立 AUTOSAR 组织,致力于建立一个标准化平台,独立于硬件的分层软件架构,制定各种车辆应用接口规范和集成标准,AUTOSAR是基于 OSEK/VDX 发展出来的,但涉及的范围更广。
AUTOSAR 主要包括 Classic Platform AUTOSAR(CP)和Adaptive PlatformAUTOSAR(AP)两个平台规范:CP AUTOSAR 是基于 OSEK/VDX 标准的,广泛应用于传统嵌入式 ECU 中,如发动机控制器、电机控制器、整车控制器、BMS 控制器等;APAUTOSAR基于 POSIX,主要应用于自动驾驶等需求高计算能力、高带宽通信、分布式部署的下一代汽车应用领域中。

狭义 OS 仅包含内核(如 QNX、Linux),广义 OS 从下至上包括从BSP、操作系统内核、中间件及库组件等硬件和上层应用之间的所有程序。QNX、Linux 是目前常见内核 OS,VxWorks 也有一定应用。随着WinCE 停止更新逐渐退出,OS 内核的格局较为稳定,主要玩家为 QNX(Blackberry)、Linux(开源基金会)、VxWorks(风河)。其中 Linux 属于非实时操作系统,而QNX 和VxWorks属于实时操作系统,WinCE 是微软开发的嵌入式操作系统,正在逐步退出汽车操作系统市场。 (1)Blackberry QNX: QNX 是遵从 POSIX 规范的类 UNIX 实时操作系统,是全球第一款达到ASILD级别的车载操作系统,优点是稳定性和安全性非常高,QNX 依靠其微内核架构实现性能和可靠性的平衡,主要特点有内核小、代码少以及故障影响小,驱动等错误不会导致整个系统都崩溃,通用、沃尔沃、奥迪、上汽等均用QNX 作为自动驾驶OS。但缺点是 QNX 作为非开源系统,兼容性较差,开发难度大,在娱乐系统开发中应用不多,主要是开放性不够,应用生态缺乏。 (2)Linux(Android): Linux 是基于 POSIX 和 UNIX 的开源操作系统,可适配更多的应用场景,具有很强的定制开发灵活度,主要用于支持更多应用和接口的信息娱乐系统场景。Android是谷歌基于 Linux 内核开发的开源操作系统,主要应用在车载信息娱乐系统、导航领域,在国内车载信息娱乐系统领域占据主流地位。由于其完全开源,基于Linux 开发的难度也极大,而且开发周期比较长,这就限制了车机系统进入门槛。(3)VxWorks: VxWorks 由 Wind River 设计开发的嵌入式实时操作系统,以其良好的可靠性和卓越的实时性被广泛地应用在通信、军事、航空、航天等领域,VxWorks 由400多个相对独立的目标模块组成,但与 Linux 相比,VxWorks 需要收取高昂的授权费,开发定制成本较高,这限制了其市场占有率的增长。

QNX、Linux 是当前车机 OS 内核的首选。根据赛迪顾问的统计,QNX 由于其典型的实时性、低延时、高稳定等特征,2021 年 QNX 市占率达到43%,是当前市占份额最高的车机 OS,已应用在包括宝马、奥迪、奔驰等超过40 个品牌,全球使用了QNX 的汽车超 1.75 亿辆;Linux(含 Android)Linux 版本丰富,经过改造Linux内核也将具备实时性功能,21 年市占率 35%;WinCE 当前市占率8%,呈现快速下滑态势,未来可能将逐步在市场消失;VxWorks 同时具备实时性及开源特点,但其业务重点一直在复杂工业领域,对于汽车产业投入较少,售价及维修费用极其昂贵,目前仅在部分高端品牌车型上有所尝试。
随着智能座舱和智能驾驶的进步,OEM 厂商更加关注车机OS。然而,无论是传统OEM 巨头或是造车新势力,从零开始开发操作系统都绝非易事,根据对基础系统的改造程度不同,一般可以分为三类: (1)定制型车机 OS:在基础 OS 的基础上进行深度开发和定制(包括系统内核修改),与 Tier1 和主机厂一起实现座舱系统平台或自动驾驶系统平台。例如百度车载 OS、大众 VW.OS、特斯拉 Version; (2)ROM 型车机 OS:基于 Android 或 Linux 定制开发,无需更改系统内核。海外主机厂多选择基于 Linux 开发 ROM 型车机 OS,国内自主品牌则主要选择应用生态更好的 Android。例如奔驰、宝马、蔚来、小鹏等整车厂的车机系统都属于ROM型车机 OS;(3)超级汽车 APP:并非完整的车机 OS,而是手机映射系统,是指集地图、音乐、语音、社交等功能于一体的多功能 APP,满足车主需求。例如百度Carlife、华为HiCar、苹果 CarPlay、谷歌 AndroidAuto 等。
板级支持包 BSP:主板硬件与操作系统之间的桥梁
BSP(Board Support Package,板级支持包)是构建嵌入式操作系统所需的引导程序、内核、根文件系统和工具链提供的完整的软件资源包。对于具体的硬件平台,与硬件相关的代码都被封装在 BSP 中,由 BSP 向上提供虚拟的硬件平台,BSP与操作系统通过定义好的接口进行交互。 BSP 介于主板硬件和操作系统之间的一层,也属于操作系统的一部分,主要目的是为了支持操作系统,使之能够更好的运行于硬件主板,为OS 和硬件设备的交互操作搭建了一个桥梁。由于所属的中介位置,BSP 的功能分为两部分,一方面为 OS 及上层应用程序提供一个与硬件无关的软件平台,另一方面OS 可以通过BSP来完成对指定硬件的配置和管理。 不同的操作系统对应于不同定义形式的 BSP。例如,VxWorks 的BSP 和Linux的BSP 相对于某一 CPU 来说尽管实现的功能一样,但写法和接口定义是完全不同的,所以写 BSP 一定要按照该系统 BSP 的定义形式来写,这样才能与上层OS 保持正确的接口,良好的支持上层 OS。

Hypervisor:虚拟化平台,跨平台应用的重要途径
提供平台虚拟化的层称为 Hypervisor。虚拟化是通过某种方式隐藏底层物理硬件的过程,从而实现多个操作系统可以透明地使用和共享硬件。Hypervisor是实现跨平台应用、提高硬件利用率的重要途径。车载领域的Hypervisor 负责管理并虚拟化异构硬件资源,以提供给运行在 Hypervisor 之上的多个操作系统内核。Hypervisor 支持异构硬件单元(包括控制单元、计算单元、AI 单元)的隔离,在同一个异构硬件平台上支持不同的操作系统内核,从而支持不同种类的应用。Hypervisor 虚拟机管理助力多系统融合。Hypervisor(虚拟机)是运行在物理服务器和操作系统之间的中间软件层,可用于同步支持Android、Linux、QNX多系统。根据 ISO26262 标准规定,仪表盘的关键数据和代码与娱乐信息系统属于不同等级,主流市场中,QNX 或 Linux 系统用来驱动仪表系统,信息娱乐系统则以Android 为主,目前技术只能将两个系统分开装置在各自芯片中。然而,虚拟机可以同时运作符合车规安全标准的 QNX 与 Linux,因此虚拟机管理的概念被引入智能座舱操作系统。 随着液晶仪表以及其他安全功能的普及,供应商不需要装载多个硬件来实现不同的功能需求,只需要在车载主芯片上进行虚拟化的软件配置,形成多个虚拟机,在每个虚拟机上运行相应的软件即可满足需求。引入虚拟机管理最重要的意义在于虚拟机可以提供一个同时运行两个及以上独立操作系统的环境,比如在智能座舱中同时运行 Android(座舱 OS)和 QNX(车控 OS),为智能网联汽车的应用提供高性价比且符合安全要求的平台。
中科创达、武汉光庭信息、南京诚迈科技是黑莓 VAI 项目的系统集成商类的合作伙伴。2017 年 3 月,黑莓公司宣布正式成立 VAI(Value-Added Integrator)项目,拓展嵌入式软件市场,成为黑莓公司 VAI 项目合作伙伴,将基于黑莓的嵌入式技术提供集成服务、安全关键型解决方案,包括黑莓QNX Neutrino 实时操作系统、QNX Momentics 工具套件、QNX 管理程序、应用程序和媒体QNX SDK、QNX无线架构、QNX 认证操作系统、QNX 医用操作系统、Certicom 工具包、Certicom管理的公钥基础设施以及 Certicom 资产管理系统。目前,黑莓VAI 项目的中国区系统集成商类的合作伙伴主要包括中科创达、武汉光庭信息、南京诚迈科技等。

长期看,智能座舱与自动驾驶两大系统终将走向融合。由于目前车控域与座舱域两者的发展目标平行,同时,由于 QNX、Linux 与 Andriod 三大系统各有优劣,因此,通过虚拟机管理多个独立系统是当下实现“多快好省”的智能网联汽车的发展路径。但从长期看,想要真正实现高级自动驾驶的必要前提就是车控与座舱的融合,即智能座舱与自动驾驶系统的容二虎,这样将会从整体层面给未来留下更系统的升级空间。当然两大系统的融合也面临着系统叠加导致的片负载加重,对计算性能形成挑战。
中间件层:助力软硬件解耦分离,提升应用层开发效率
中间件隔离应用层与底层硬件,助力软硬件解耦。中间件位于操作系统、网络和数据库之上,应用软件的下层,作用是为处于自己上层的应用软件提供运行与开发的环境,帮助用户灵活、高效地开发和集成复杂的应用软件,实现软硬件的解耦分离。车企致力于定义更统一的中间件通信和服务,以降低开发成本和系统复杂度,操作软件(OS)和中间件是促进软硬件分离的底层软件组件。即使车企选择自研操作系统,但同时也会依赖于供应商提供标准中间件产品,尤其基础软件平台的架构极其重要,可大幅提升应用层软件的开发效率。所有中间件方案中,最著名的是 CP AUTOSAR 的 RTE。AUTOSAR 的两个平台AUTOSARClassic 和 AUTOSAR Adaptive 为不同的车辆用例提供了分层的软件体系结构方法,AUTOSAR 以中间件 RTE(Runtime Environment)为界,隔离上层的应用层(Application Layer)与下层的基础软件(Basic Software)。RTE 使得硬件层完全独立于应用层,OEM 厂商可以专注于开发特定的、有竞争力的应用软件,同时使得厂商不关心的基础软件层被标准化。
分布式通信(Data Distribution Service, DDS)通过实现低延迟数据连接、极高的可靠性和可扩展的灵活架构,使数据成为未来移动数字平台的中心。DDS提供的用于以数据为中心的连接的中间件协议、连接框架和API 标准。它集成了分布式系统的组件,提供了低延迟的数据连接、极高的可靠性和可扩展的体系结构,满足业务和任务关键型应用程序的需求。AUTOSAR Adaptive 平台2017 年推出,2018 年便集成了 DDS 标准,将 DDS 与 AUTOSAR 结合使用,不仅可以保证和扩展AUTOSAR 系统内部互操作性的功能,而且还可以将其开放给来自不同生态系统等行业的外部系统。

国产 AUTOSAR 供应商不断崛起。AUTOSAR 标准发展了十多年,已经形成非常复杂的技术体系。各工具厂商开发了相应的支撑软件,以助力主机厂加速实现AUTOSAR的落地。目前全球知名的 AUTOSAR 解决方案厂商包括ETAS(博世)、EB(大陆)、Mentor Graphics(西门子)、Wind River、Vector、KPIT 等,国内主要是东软睿驰、经纬恒润等。
功能软件:自动驾驶的核心共性功能模块
功能软件主要包含自动驾驶的核心共性功能模块。核心共性功能模块包括自动驾驶通用框架、网联、云控等,结合系统软件,共同构成完整的自动驾驶操作系统,支撑自动驾驶技术实现。
(1)智能驾驶通用模型: 智能驾驶通用模型是对智能驾驶中智能认知、智能决策和智能控制等过程的模型化抽象。对应于自动驾驶中环境感知、决策与规划、控制与执行三大部分,通用模型也可以分为环境模型、规划模型和控制模型等。自动驾驶会产生安全和产品化共性需求,通过设计和实现通用框架模块来满足这些共性需求,是保障自动驾驶系统实时、安全、可扩展和可定制的基础。
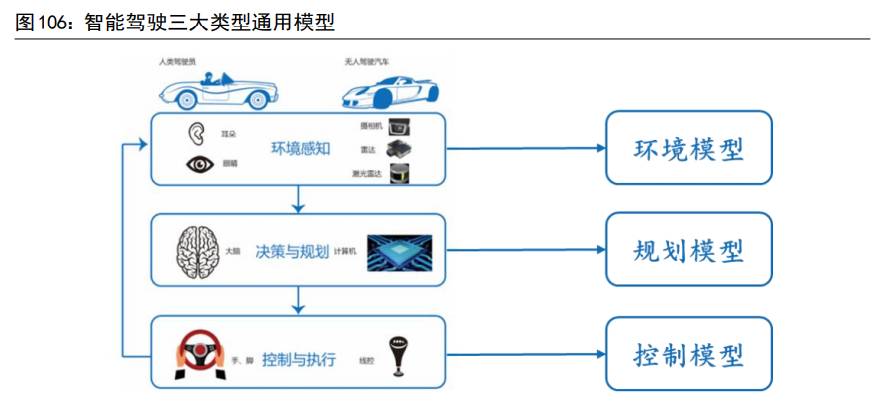
(2)功能软件通用框架: 功能软件通用框架是承载智能驾驶通用模型的基础,是功能软件的核心和驱动部分,可以分为数据流框架和基础服务两部分。 数据流框架向下封装不同的智能驾驶系统软件和中间件服务,向智能驾驶通用模型中的算法提供与底层系统软件解耦的算法框架。数据流框架的主要作用是对智能驾驶通用模型中的算法进行抽象、部署、驱动,解决跨域、跨平台部署和计算的问题。 基础服务是功能软件层共用的基本服务,包括可靠冗余组件、信息安全基本服务以及网联云控服务等。其中,可靠冗余组件是保证自动驾驶安全可控的关键,也是车控操作系统取得操作系统全栈功能安全认证的重要保障;信息安全基础服务为车端数据定义了数据类型和安全等级,为车端功能和应用定义的数据处理功能定义;网联云控服务可提供操作系统的安全冗余信息、超视距信息和通用模型的信息。
(3)数据抽象: 数据抽象可以为上层各模型提供数据源。通过对传感器、执行器、自车状态、地图以及来自云端的接口等数据进行标准化处理,数据抽象的过程可以为智能驾驶通用模型提供各种不同的数据源进而建立异构硬件数据抽象,达到功能和应用开发与底层硬件的解耦和依赖。一般来说,数据抽象可以分为分类、聚集与概括三种类型。
工具链:提升平台软硬件研发效率的重要途径
车载计算平台开发的软硬件环境以及全栈工具链成为提升开发效率的重要途径之一。高阶自动驾驶技术不断迭代,车载计算平台的研发更需要对产品进行整体持续的迭代,而不只是针对单一的模块,或者其中几个功能。全栈式工具链主要包括开发工具、集成工具、仿真工具、调试工具、测试工具等。
应用软件:OEM 品牌智能化产品力的直接体现
应用软件作为系统软件与功能软件之上独立开发的软件程序,更是OEM 品牌智能化产品力的直接体现。应用软件主要包括面向自动驾驶算法、地图导航类、车载语音、OTA 与云服务、信息娱乐等。
(1)自动驾驶算法 。自动驾驶算法是决定车辆智能化水平的关键所在。自动驾驶算法覆盖感知、决策、执行三个层次。感知类算法,SLAM(Simultaneous localization and mapping,同步定位与建图)算法是一个重要分支,SLAM 算法根据点云数据传感器的不同又可分为视觉 SLAM 算法、激光 SLAM 算法以及多传感器融合算法;决策类算法包括自动驾驶规划算法、自动驾驶决策算法;执行类算法主要为自动驾驶控制算法。

(2)高精度地图。高精度地图,即 HD Map(High Definition Map)或HAD Map(Highly AutomatedDriving Map),是指绝对精度和相对精度均在 1 米以内的高精度、高新鲜度、高丰富度的电子地图。其信息包括道路类型、曲率、车道线位置等道路信息,路边基础设施、障碍物、交通标志等环境对象信息,以及交通流量、红绿灯状态信息等实时动态信息。
百度、四维图新、高德占据主要份额,国内市场呈现“三足鼎立”。由于地图导航类业务的资质限制,国内高精度地图主要玩家大多是本土公司,根据IDC统计,2020 年国内高精度地图行业市场份额前五名公司为百度、四维图新、高德、易图通以及 Here,其中 CR3 超过 65%,呈现“三足鼎立”的局面。预计 2025 年国内市场规模达 32 亿美元。按照 3 亿辆汽车保有量及单车百元年服务费测算,国内市场规模将从 2020 年的 6.4 亿美元增长到2025 年的32亿美元,预计 2025 年全球市场份额将达到 35.6%,CAGR 达到38.0%,高于同期全球增速。
(3)车载语音 。车载语音是车内最简洁、最人性化、最安全的交互方式,也是未来最主要的车内交互方式。随着 AI 和硬件性能的增强,语音交互是未来汽车的绝对主流。语音交互主要是依靠 NLP 算法对语音进行解析,使得自动驾驶系统更容易理解驾驶员的指令。2020 年智能座舱中自然语音识别搭载率大约为67%,预计2024 年可达84%。目前,国内乘用车车载语音装配率超过 64.8%,大大提高了行车安全性以及便捷性。 科大讯飞与 Cerence 领先中国车载语音市场,互联网企业及车厂纷纷入局。竞争格局方面,根据高工汽车统计数据显示,Cerence 市占率为39.5%,排名第一,Cerence 作为全球车载语音的龙头,客户主要以合资车型为主;科大讯飞是中国车载语音市场的领头羊,市占率超过 38%,排名第二;互联网企业方面,BAT也已分别入局车载语音,其中百度发展更为迅速,市场份额7.2%。腾讯目前主打车载应用“腾讯随行”和“腾讯爱趣听”等生态服务上车,排名第五;此外,大众问问凭借其主机厂的背景优势入局,凭借大众、奥迪等多款前装车型市场占有率快速提升。

海外对标研究(特斯拉、英伟达、高通、Mobileye)
特斯拉(TESLA):从硬到软的全栈自研,打造“算力+算法+数据”的竞争壁垒
特斯拉于 2014 年推出自动驾驶辅助系统 Autopilot 1.0,特斯拉掌握核心数据、AI 算法以及主控芯片,从硬到软的全栈自研,这也成为了特斯拉最核心的竞争壁。特斯拉成立于 2003 年,并于 2010 年在纳斯达克上市。2008 年至2020 年特斯拉共发布 Model S、Model X、Model 3、Model Y 四款量产车型。特斯拉于2013年开始自动驾驶辅助系统的研发,并于 2014 年特斯拉推出自动驾驶辅助系统Autopilot 1.0,此后经历四次升级,并在 2019 年在HW 3.0 平台上推出了自研的FSD(Full Self-Driving Computer)主控芯片。
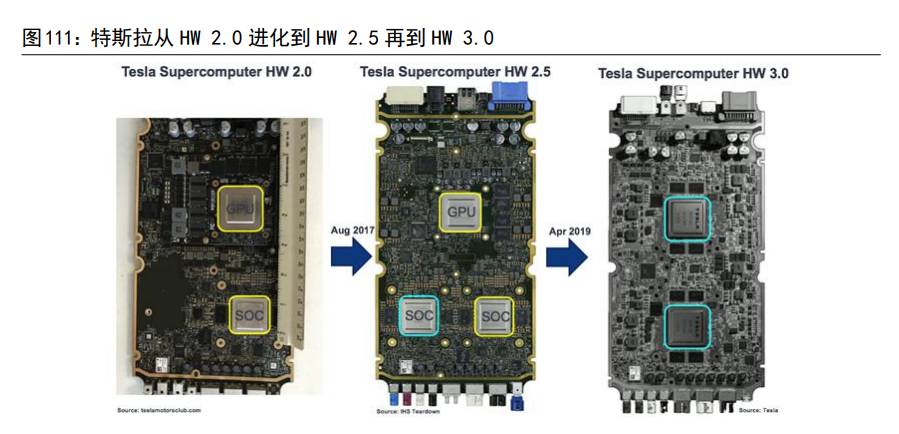
特斯拉从 Mobileye 到英伟达,最终走向 FSD 自研芯片。特斯拉从2014年推出HW 1.0 开始,特斯拉 Autopilot 系统共经历了 4 次大的硬件版本更新。在2014年-2016 年的 HW 1.0 时代,特斯拉完全基于 1 颗 Mobileye EyeQ3 和1 颗NVIDIATegra 3,算法也完全由第三方供应商 Mobileye 提供,2016 年特斯拉逐渐不满于Mobileye 进程缓慢以及相关安全事故,并在 2016 年的HW 2.0 版本上,特斯拉切换到了由 1 颗 NVIDIA Parker SoC 和 1 颗 NVIDIA Pascal GPU 组成的NVIDIADRIVEPX 2 计算平台,而在 2017 年的 HW 2.5 版本升级过程中,将NVIDIA DrivePX2升级为 NVIDIA Drive PX 2+,新增了一个 NVIDIA Parker SoC,获得了80%左右的运算性能提升。 特斯拉即将发布 HW 4.0 平台,基于三星 7nm 工艺的FSD 自研芯片,其性能将是HW 3.0 的三倍。由于英伟达的高能耗,2017 年起,马斯克决定开始自研主控芯片,尤其是主控芯片中的神经网络算法和 AI 处理单元全部由特斯拉自主完成。在2019年 4 月份,特斯拉在 Autopilot HW 3.0 平台上成功推出自研的FSD 主控芯片,实现了自动驾驶芯片+神经网络算法的垂直整合。特斯拉计划将在不久的未来HW4.0版本,基于三星 7nm 工艺的全新 FSD 自研芯片,其性能将是HW 3.0 的三倍。
特斯拉 FSD 芯片是以 NPU(ASIC)为计算核心,采用“CPU+GPU+ASIC”的技术路线,FSD 主要有三个模块 CPU、GPU 和 NPU。特斯拉于2019 年推出自研的FSD芯片,并在其 Model S、Model X、Model 3 上批量交付 FSD 芯片。该芯片采用三星14nmFinFET 工艺制造,面积为 260 平方毫米,封装了大约60 亿个晶体管。(1)CPU:Cortex-A72 架构,共三组、每组 4 个核,一共有 12 核、最高运行频率2.2GHz,CPU 主要处理通用的计算和任务;(2)GPU:最高工作频率为1 GHz 的GPU,最高计算能力为 600 GFLPS;(3)NPU:2 个 Neural Processing Unit(NPU),每个NPU 可以执行 8 位整数计算,运行频率为 2GHz,单个NPU 算力36.86 TOPS,2个NPU 的总算力为 73.73 TOPS。从面积来看,NPU 面积占比最大,NPU 主要用于运行深度神经网络,GPU 主要用于运行深度神经网络的post processing,处理深度神经网络的部分合计占据了芯片 70%的面积。
特斯拉 HW 3.0 采用完整的双系统冗余。特斯拉 HW 3.0 的主板上共搭载了两块的自研芯片,双芯片的目的是作为安全冗余,互相对照,每块芯片可以独立运算。每块芯片周围有四块镁光 DRAM 内存,每块芯片分别配有一块东芝闪存芯片,用于承载操作系统和深度学习模型,主板的右侧是视频输出接口,左侧是电源接口和其他另外的输入/输出接口。此外,特斯拉还设计了冗余的电源、重叠的摄像机视野部分、各种向后兼容的连接器和接口。特斯拉 HW 3.0 采用完整的双系统冗余,在任何一个功能区域发生损坏时,整个系统依旧可以正常工作,确保车辆能安全行驶。HW 3.0 的性能比上一代 HW 2.5 提高了 21 倍,而功耗降低25%,能效比2TOPS/W。

特斯拉 FSD 在全球的整体开通率约为 11%,其中北美地区比例最高。根据Troyteslike 数据显示,受到低价的 Model 3 及 Model Y 高速放量,以及FSD不断涨价的影响,特斯拉 FSD 在全球的整体开通率持续下滑,截至2021Q2结束,特斯拉 FSD 的整体开通率约为 11%。预计特斯拉 FSD 在全球的累计开通数量近36万套(北美超过 26 万套,欧洲接近 9 万套,亚太地区仅5700 套),平均选装价格为 6 千美元,其总销售额超过 210 亿美元。特斯拉FSD 在亚洲地区销量持续攀升,但是 FSD 开通率整体偏低。以北美地区为例,Model S/X 的FSD 选装率在61%,ModelY 的选装率在 20%,Model 3 的选装率在 20%。
特斯拉依托庞大客户群来收集自动驾驶数据,从而实现对深度学习系统的模型训练。与一般的汽车厂商和科技公司不同,特斯拉的自动驾驶不是依靠内部测试获取自动驾驶的数据,而是通过其庞大的客户群和装载传感器的特斯拉车辆上收集数据,并进行功能升级。即使没有激活,AP 系统仍可以收集有关其环境和潜在自动驾驶行为的数据,以馈送特斯拉的神经网络。该数据收集方法通常被称为影子模式(Shadow mode),即 AP 系统在车辆的后台运行而无法在驾驶中进行任何输入。
发布 7nm 工艺 AI 训练芯片 D1,打造 Dojo 超算训练平台。在2021 年8 月的特斯拉 AI Day 上,特斯拉发布了最新的 AI 训练芯片 D1,D1 芯片采用台积电7nm工艺制造,核心面积达 645 平方毫米,集成了多达 500 亿个晶体管,共有四个64位超标量 CPU 核心,拥有多达 354 个训练节点,特别用于8×8 乘法,支持FP32、BFP64、CFP8、INT16、INT8 等各种数据指令格式,都是 AI 训练相关。D1 芯片的FP32单精度浮点计算性能达 22.6 TFlops,BF16/CFP8 计算性能则可达362 TFlops。为了支撑 AI 训练的扩展性,D1 芯片的互连带宽最高可达10TB/s,由多达576个通道组成,每个通道的带宽都有 112Gbps,而热设计功耗仅为400W。Dojo 是一种通过网络连接的分布式计算机架构,它具有高带宽、低延时等特点,将会使人工智能拥有更高速的学习能力,从而使 Autopilot 更加强大。Dojo超级平台的内核是 D1 芯片,25 个 D1 芯片组建成一个“训练瓦”(Trainingtile),组成 36 TB/s 的带宽和 9 Peta FLOPS(9 千万亿次)算力。未来,Dojo 还可以组合成为全球最强算力的超级计算机集群。

英伟达(NVIDIA):打造全栈式工具链,持续领先高阶自动驾驶
英伟达自 2015 年推出 NVIDIA Drive 系列平台,赋能自动驾驶生态。英伟达自2015年开始推出面向座舱的 DRIVE CX 和面向驾驶的 DRIVE PX,此后先后推出DRIVEPX2、Drive PX Xavier、DRIVE PX Pegasus、DRIVE AGX Orin 等多个自动驾驶平台,而在 SoC 芯片方面,从 Parker、Xavier、Orin 到最新发布的Atlan。(1)DRIVE PX: 英伟达在 CES 2015 上推出了基于英伟达 Maxwell GPU 架构的第一代平台:搭载1颗 Tegra X1 的 DRIVE CX,主要面向数字座舱,以及搭载2 颗Tegra X1 的DRIVEPX,主要面向自动驾驶; (2)DRIVE PX2: 英伟达在 CES 2016 推出了基于英伟达 Pascal GPU 架构的第二代平台DRIVEPX2,主要由 Tegra X2(Parker)和 Pascal GPU 组成,PX2 有多个版本,主要可以分为单芯片版的 Auto Cruise、双芯片版的 Auto Chauffeur 以及四芯片版的FullyAutonomous Driving。特斯拉自 2016 年 HW 2.0 开始搭载英伟达的定制版DRIVEPX2Auto Cruise 版本,并在 2017 年的 HW 2.5 上升级为2 颗Tegra X2(Parker);
(3)Drive PX Xavier: 英伟达在 CES 2017 上推出了 Xavier AI Car Supercomputer,并在CES2018上重新发布命名为 Drive PX Xavier,搭载一颗 30 TOPS 算力的Tegra Xavier芯片。Xavier 平台是 PX2 的小型化高能效版,算力稍有提升的前提下,面积缩小为PX2的一半,功率仅为 PX2 的 1/8 左右。该平台目前搭载在小鹏P5 与P7 车型上。(4)DRIVE PX Pegasus: 英伟达在 2017 年 10 月推出了 DRIVE PX Pegasus,Pegasus 定位更注重性能的提升。Pegasus 共有四颗芯片,2 颗 Tegra Xavier 芯片,2 颗单独的Turing架构的GPU,每颗 Xavier 集成了一颗 8 核 CPU 和一个英伟达Volta 架构的GPU,通过增加 CPU 和 GPU,Pegasus 平台可以实现 320 TOPS 的算力,功耗500 W。(5)DRIVE AGX Orin: 英伟达在中国 GTC 2019 大会上推出了 DRIVE AGX Orin 平台,该平台由2颗OrinSoC 芯片和 2 颗 Ampere 架构的 GPU,最高算力达到2000 TOPS,功耗800W。

单颗 Orin SoC 可实现 254 TOPS 算力,功耗低于 55W,可支持单片或多片协同方案,实现算力扩展。Orin SoC 芯片集成了 Arm Hercules CPU 内核、新一代架构Ampere 的 GPU 、全新深度学习加速器(DLA)和计算机视觉加速器(PVA),可实现每秒 254 TOPS 运算性能,相比上一代 Xavier 系统级芯片运算性能提升了7倍。在运算性能提升巨大的情况下,Orin 的功耗低于55 W。Orin 可以覆盖10TOPS到 254 TOPS 的算力需求、可以为终端用户提供可升级的方案支持单片或多片Orin协同的解决方案,无限扩展算力。 Orin 所集成的 GPU 拥有 2048 个 CUDA Core 和 64 个Tensor Core。Orin 内部集成了 Ampere 架构 GPU,该 GPU 拥有 2 个 GPC(Graphics Processing Clusters,图形处理簇),每个 GPC 包含 4 个 TPC(Texture Processing Clusters,纹理处理簇),每个 TPC 包含 2 个 SM(Streaming Multiprocesor,流处理器),每个SM下包含包含 128 个 CUDA Core,合计 2048 个 CUDA Core,算力为4096 GFLOPS。此外,还包括 64 个 Tensor Core(张量核),Tensor Core 是专为执行张量或矩阵运算而设计的专用执行单元,稀疏 INT8 模型下算力达131 TOPS,或者密集INT8下 54 TOPS。
蔚来 ET7 成为 Orin 系列的首发量产车,NIO Adam 超算平台搭载四颗Orin芯片,单车算力打造 1016 TOPS。蔚来 NIO Adam 超算平台,配备四颗Orin 芯片,Adam拥有 48 个 CPU 内核,256 个矩阵运算单元,8096 个浮点运算单元,共计680亿个晶体管,总算力高达 1016 TOPS。Adam 平台集成了安全自主运行所需的冗余和多样性,在 4 颗 Orin SoC 中,前两颗 Orin SoC 负责处理车辆传感器每秒产生的高达 8G 的数据量,第三颗 Orin SoC 作为后备,以确保系统能够在任何情况下安全运行,第四颗 Orin SoC 可进行本地的模型训练,进一步提升车辆自身的学习能力,并基于用户偏好提供个性化驾驶体验。蔚来 ET7 将作为NVIDIA DRIVE Orin系列的首发量产车于 2022 年 3 月开始交付,同样搭载NIO Adam 超算平台的蔚来ET5将于 2022 年 9 月开始交付。

当前,英伟达在自动驾驶领域遥遥领先,持续获得大量自动驾驶客户,英伟达的客户大致可以分为三类:造车新势力、传统车企、自动驾驶公司。(1)造车新势力:蔚来(ET5、ET7)、小鹏(P5、P7、G9)、理想(X01)、威马(M7)、上汽智己、R 汽车、FF 等;(2)传统车企:奔驰、沃尔沃、现代、奥迪、Lotus等;(3)自动驾驶 Robotruck/Robotaxi 公司:通用 Cruise、亚马逊Zoox、中国的滴滴,沃尔沃商用车、Kodiak、图森未来、智加科技、AutoX、小马智行、文远知行等。
英伟达提供包括从芯片、硬件平台、系统软件、功能软件、应用软件以及仿真测试平台和训练平台在内的全栈工具链。以英伟达 DRIVE AGX 硬件开发平台为起点,在 DRIVE Constellation 上验证软件算法。充分验证后将部署软件,通过DRIVEHyperion 参考架构进行上路测试。利用 DGX 高性能训练服务器进行深度学习模型训练,此过程反复迭代。英伟达提供了从芯片(Xavier/Orin/Atlan)、DRIVEAGX硬件平台、DRIVE OS、Driveworks、DRIVE AV 自动驾驶软件栈、DRIVE Hyperion数据采集和开发验证套件 、DRIVE Constellation 虚拟仿真平台和DGX 高性能训练平台等全栈工具链。
(1)应用软件:DRIVE AV 与 Drive IX 软件栈。 DRIVE AV 软件栈主要面向自动驾驶域,包括了从规划、地图到感知的应用软件开发,帮助开发者实现端到端的感知、路径规划、地图构建、决策和控制等功能的开发;Drive IX 主要面向智能座舱域,集成了视觉、语音和图形用户体验,包括可视化(盲区可视化、自动驾驶可视化以及驾驶员监控可视化等)、AI 辅助驾驶(DMS、神经网络、摄像头标定等)以及 AI 助手(语音识别、手势识别、面容识别等)。
(2)功能软件(中间件):Driveworks 。DriveWorks 是所有自动驾驶汽车软件开发的基础,包含了高阶自动驾驶开发所需要的处理模块、工具和框架。DriveWorks 是模块化、开放、易于定制的,方便开发人员在自己的软件堆栈中实现深度定制开发。包括DNN 算法加速库、Calibration 标定工具、Drive Core 核心库(传感器抽象层、车辆I/O、图像处理、点云处理、DNN 框架等。
(3)系统软件:DRIVE OS 。DRIVE OS 提供了一套参考操作系统和相关软件栈,专为在基于AGX 硬件平台上的开发与部署,相关的基础软件栈包括 RTOS、Hypervisor、英伟达CUDA 和TensorRT等其他组件,这些组件经过优化后可直接访问 AGX 硬件平台。DRIVE OS SDK利用所有软件、库和工具、技术和 API,为自动驾驶汽车的构建、调试、配置和部署应用程序,提供了优化的工作流。
(4)硬件平台:DRIVE AGX 平台 。英伟达 DRIVE AGX 开发工具包提供了开发展所需要的硬件、软件及示例应用程序。英伟达的历代硬件计算平台 DRIVE PX2、Drive PX Xavier、DRIVE PX Pegasus、DRIVE AGX Orin 等,前文已经详细介绍。DRIVE AGX 平台提供开放的软件框架,以及与硬件计算平台相配套的完善的开发工具包;此外,英伟达应有众多Tier1及传感器产业合作伙伴,提供摄像头、毫米波雷达、超声波雷达、激光雷达等车载传感器。
(5)仿真平台:DRIVE Constellation 与 DRIVE Sim 。DRIVE Constellation 自动驾驶车辆仿真平台主要完成对各种虚拟场景的渲染、仿真,产生模拟传感器数据,通过运行 DRIVE Sim 仿真软件,模拟仿真汽车在仿真环境中行驶可产生的传感器数据。Constellation 仿真平台提供可扩展、全面且多样化的测试环境。借助开放的模块化架构,DRIVE Sim 仿真软件可让客户利用自己的仿真模型或生态合作伙伴的自定义车辆、环境、传感器或交通场景。
(6)训练平台:NVIDIA DGX 。基于高性能的英伟达 DGX AI 服务器,客户可以进行深度网络学习的训练、推理和数据分析,同时多台 DGX 构建超级计算机或者人工智能集群,为具有挑战性的自动驾驶海量数据进行深度学习网络模型训练和建图提供出色的基础设施和灵活可扩展的 AI 计算性能。

英伟达发布全新自动驾驶软硬件开发参考平台 DRIVE Hyperion 8。在2021年英伟达 GTC 大会上,英伟达发布了自动驾驶软硬件开发参考平台DRIVE Hyperion8,允许主机厂客户访问和调整其需求,包括核心计算和中间件以及车辆内部AI功能等。该计算平台可用于 2024 年车型,硬件方面,搭载了两颗Orin 芯片,每颗算力 254TOPS,支持 12 颗摄像头、9 个毫米波、12 个超声波雷达和1 颗激光雷达。提供传感器硬件的供应商包括 Luminar(激光雷达)、Hella(短程毫米波雷达)、Continental (远程毫米波雷达)、Sony(摄像头组件)、Valeo (摄像头组件、超声波雷达)。(报告来源:未来智库)
高通(Qualcomm):智能座舱一骑绝尘,自动驾驶不断追赶
高通是作为消费电子霸主,持续布局智能网联汽车业务。高通(Qualcomm)公司成立于 1985,高通自 2002 年开始布局汽车业务,早期专注于车载网联解决方案,高通于 2014 年推出了第一代座舱平台骁龙 602A,在2016 年推出第二代座舱平820A,在 2019 年推出第三代座舱平台 8155,并于2021 年发布第四代座舱平台8295;在自动驾驶领域,高通于 2019 年发布了 Ride 自动驾驶平台。高通目前已拥有 25 家以上的头部车企客户,公司业务已经覆盖全球超过2 亿辆的智能网联汽车,高通在智能汽车领域的版图不断扩张。
高通基于车云、座舱、驾驶及车联四大平台打造数字底盘。高通在汽车业务领域志在打造“数字底盘”,主要由四部分组成:骁龙车云平台(SnapdragonCar-to-Cloud)、骁龙座舱平台(Snapdragon Cockpit Platform、骁龙驾驶平台(Snapdragon Ride Platform)、骁龙车联平台(Snapdragon Auto connectivityPlatform),打造开放、可定制、可升级、智能互联的电子底盘,帮助Tier1和 OEM 主机厂提升客户体验。

高通在智能座舱芯片领域一骑绝尘。从高通 2014 年推出第一代座舱芯片602A开始,再到第二代 820A 以及第三代 8155 芯片,市场渗透率持续提升,能够发现,近期最初的新车型其座舱几乎都是搭载了高通 8155 芯片。目前,包括奔驰、奥迪、保时捷、捷豹路虎、本田、吉利、长城、广汽、比亚迪、领克、小鹏、理想智造、威马汽车在内的国内外领先汽车制造商均已推出或宣布推出搭载骁龙汽车数字座舱平台的车型。
高通骁龙 SA8155P 芯片是目前量产车可以选用的性能最强的座舱SoC 芯片。高通第三代座舱芯片 SA8155P 平台是基于台积电第一代7nm 工艺打造的SoC,也是第一款 7nm 工艺打造的车规级数字座舱 SoC,性能上,8155 芯片是目前量产车可以选用的性能最强的座舱 SoC 芯片,目前全球最大的25 家车企已有20 家采用高通第三代座舱 8155 芯片。8155 平台属于多核异构的系统,性能是原820 平台的三倍,该平台拥有极强的异构计算的能力,包括多核AI 计算单元、SpectraISP、Kryo 435 CPU、Hexagon DSP 第六代 Adreno 640 GPU。Hexagon DSP 中增加了向量扩展内核(Hexagon Vector eXtensions,HVX)和张量加速器(HexagonTensorAccelerator,HTA),这些专用 AI 计算模块能大幅提高芯片的AI 算力。
高通发布第四代智能座舱 SA8295P 平台,性能显著提升。2021 年7 月,高通发布了第四代座舱平台的 SA8295P,采用 5nm 制程,采用第六代八核Kyro 680CPU和Adreno 660 GPU,支持同步处理仪表盘、座舱屏、AR-HUD、后座显示屏、电子后视镜等多屏场景需求,CPU、GPU 等主要计算单元的计算能力较8155 提升50%以上,主线能力有超过 100%的提升。
百度旗下集度汽车成为高通 8295 的首发,量产车型预计在2023 年交付。2021年11 月 29 日,集度、百度和高通三方在上海进行了签约仪式,集度汽车成为高通8295 的首发,集度旗下首款汽车机器人预计将于 2023 年量产交付,此外高通8295芯片已经获得长城、广汽、通用等车厂的定点,相关车型预计在2023 年交付。中科创达在 CES 2022 发布基于高通 SA8295 硬件平台的全新智能座舱解决方案。该解决方案充分发挥 SA8295 在算力、图形、图像处理等方面的突出性能,打造了包含数字仪表、中控娱乐、副驾娱乐、双后座娱乐、流媒体后视镜和抬头显示器的一芯多屏智能座舱域控。公司基于深厚的车载 OS 技术,创新性地打通座舱和自驾两大技术域,更好地支持 360°环视和智能泊车功能,基于座舱域的冗余算力,在实现安全可靠的低速泊车的同时降低了方案成本。

Snapdragon Ride 软件平台包括:规划堆栈、定位堆栈、感知融合堆栈、系统框架、核心软件开发工具包(SDK)、操作系统和硬件系统。高通推出的专门面向自动驾驶的软件栈,是集成在 Snapdragon Ride 平台中的模块化可扩展解决方案,旨在帮助汽车制造商和一级供应商加速开发和创新。该软件栈通过面向复杂用例而优化的软件和应用,助力汽车制造商为日常驾驶带来更高的安全性和舒适性,例如自动导航的类人高速公路驾驶,以及提供感知、定位、传感器融合和行为规划等模块化选项。Snapdragon Ride 平台的软件框架支持同时托管客户特定的软件栈组件和 Snapdragon Ride 自动驾驶软件栈组件。
高通收购维宁尔旗下软件业务 Arriver,全面补强自动驾驶域。维宁尔(Veoneer)总部位于瑞典斯德哥尔摩,前身是全球最大的安全气囊和安全带生产商奥托立夫(Autoliv)公司电子事业部,2018 年从奥托立夫拆分出来,维宁尔致力于自动驾驶汽车的高级辅助系统(ADAS)和协作式自动驾驶系统(AD)领域的研发,拥有雷达系统、ADAS 电子控制单元(ECU)、视觉系统、激光雷达系统和热成像等产品。Veoneer 在 2020 年将 ADAS、协作和自动软件开发集中在一个部门并命名为Arriver。
集成 Arriver 视觉感知软件栈,推出 Snapdragon Ride Vision 视觉系统。高通在 CES 2022 上发布了 Snapdragon Ride Vision 视觉系统,该系统拥有全新的开放、可扩展、模块化计算机视觉软件栈,基于 4 纳米制程的系统级SoC 芯片打造,旨在优化前视和环视摄像头部署,支持先进驾驶辅助系统(ADAS)和自动驾驶(AD)。该视觉系统集成了专用高性能 Snapdragon Ride SoC 和Arriver 下一代视觉感知软件栈,提供多项计算功能以增强对车辆周围环境的感知,支持汽车的规划与执行并助力实现更安全的驾乘体验。利用 Ride 平台软件开发套件(SDK),汽车制造商和 Tier 1 可以灵活开发其驾驶策略软件栈并集成组件,带来扩展灵活性,使其能够集成地图众包、驾驶员监测系统(DMS)、泊车系统、蜂窝车联网(C-V2X)技术和定位模组,从而支持更优的定制化和向上集成。Snapdragon Ride视觉系统预计将于 2024 年量产上市。
Mobileye:ADAS 赛道的先行者,当前市占率第一
Mobileye 自 1999 年便开始专注于 ADAS 赛道。Mobileye 于1999 年由以色列希伯来大学的 Amoon Shashua 教授和 Ziv Aviram 创立,靠视觉算法起家,主要业务是开发自动驾驶相关的系统和 EyeQ 系列芯片。2007 年,Mobileye 的EyeQ1开始在宝马、通用和沃尔沃等车企量产上车,2008 年发布了EyeQ2,尤其在2014年推出EyeQ3 后一举成名,同时于 2014 年在美国纳斯达克上市,市值高达80 亿美元。在 2017 年由英特尔以 153 亿美元收购,从而私有化退市,成为英特尔旗下自动驾驶业务部门。英特尔计划在 2022 年中让 Mobileye 独立在美上市。

从 2007 年至今,Mobileye EyeQ 系列芯片累计出货量超过1 亿颗。Mobileye的EyeQ1 自 2007 年在宝马、通用和沃尔沃量产上车以来,截至目前,公司EyeQ系列芯片已经完成 1 亿颗的出货。Mobileye EyeQ 系列芯片出货量也在持续增加,但是增速逐渐放缓,EyeQ 系列芯片销量从 2018-2021 年分别为1240 万、1750万、1930 和 2810 万颗,同比增长率 43%/41%/10%/46%。
Mobileye 市场占有率依旧领先,正在逐渐掉队。在过去20 年时间里,Mobileye以视觉感知技术为基础,推出了算法+EyeQ 系列芯片组成的一系列解决方案,帮助车企实现从 L0 级的碰撞预警,到 L1 级的 AEB 紧急制动、ACC 自适应巡航,再到 L2 级的 ICC 集成式巡航等各种功能,Mobileye 当前仍然以36.29%的市场份额排名第一,包括宝马、沃尔沃、奥迪、蔚来、长城等一系列国内外车企,甚至特斯拉都曾搭载过 EyeQ 系列芯片。但是,Mobileye 正在逐渐掉队,例如,宝马在2016 年与 Mobileye 组建了自动驾驶联盟,但是在前不久已经与高通Ride达成合作,蔚来、理想等一批车企则选择了在新一代车型上搭载英伟达Orin 芯片。
EyeQ5 采用“CPU+ASIC”架构,功耗极低,但生态相对封闭。EyeQ5 主要有4个模块:CPU、Computer Vision Processors(CVP), Deep Learning Accelerator(DLA)、Multithreaded Accelerator(MA),其中CVP 是针对传统计算机视觉算法设计的 ASIC 模块,用专有的 ASIC 来运行这些算法而达到极低功耗而闻名。但是其算法系统相对封闭,对 OEM 和 Tier 1 来说是黑盒,他们无法进行二次修改从而差异化自己的算法功能。Mobileye 的算法解决方案还是以传统计算机视觉算法为主,深度学习算法为辅,这也直接决定了其以CVP 为主,DLA 为辅的架构。
Mobileye 在近年的 CES 2022 大会上发布了三款最新的芯片EyeQ Ultra、EyeQ6Light 和 EyeQ6 High。此外,Mobileye 与吉利汽车集团的极氪共同宣布,将在在2024 年前推出具有 L4 能力的纯电新车,新车基于吉利SEA 平台打造,使用6颗EyeQ 5 芯片,以处理 Mobileye 的驾驶策略及地图技术的开放协作模型。同时,新车将,双方将在软件技术方面进行有效集成。
EyeQ Ultra:面向 L4 级自动驾驶,基于 5nm 制程打造,算力176 TOPS,大约为 10 颗 EyeQ5 芯片的性能。EyeQ Ultra 具备12 核、24 线程CPU,同时还有两个通用计算加速器和两个 CNN 加速器。EyeQ Ultra 预计将在2023年提供样品,2025 年实现量产上车;
EyeQ6 High:面向 L2 级自动驾驶,基于 7nm 制程打造,算力34 TOPS,EyeQ6High 具备 8 核、32 线程的 CPU,两个通用计算加速器和两个CNN 加速器。EyeQ6High 预计 2022 年开始提供样品,2024 年实现量产;
EyeQ6 Light:面向 L1-L2 级自动驾驶,基于7nm 制程打造,算力5TOPS。EyeQ6 Light 具备 2 核、8 线程 CPU,1 个通用计算加速器和1 个CNN加速器。为上一代 EyeQ4 的迭代版本,但封装尺寸为 EyeQ4 的55%。预计2023年实现量产。
(本文仅供参考,不代表我们的任何投资建议。如需使用相关信息,请参阅报告原文。)
精选报告来源:【未来智库】。



















